前言
这篇文章主要分享几篇 DETR 和 Deformable DETR 的后续工作,包括 Effient DETR [1], PnP DETR [2], Sparse DETR [3]。 分享这几篇工作的主要原因在于它们都是 DETR 的一个方向的改进,即减少 DETR 中的计算量。DETR 利用 transformer 实现了 end-to-end 的目标检测,不需要任何额外的后处理,如 NMS, 直接从 raw images 得到目标框。DETR 首先利用 CNN 提取的 feature, 然后把二维的 feature 拍扁后得到序列长度为 \(L=W*H\) 的 feature, 然后把它们输入到 transformer 模块中, transformer 计算 L 个 feature 之间的 attention, 计算量十分庞大,复杂度相对 feature map 的长宽来说是平方级别的。Deformable DETR 通过压缩 key 值,计算每个 query 对应的 reference point 来采样新的 key, 采样的点通常特别少,如 \(K=4\), 把 DETR 中 self-attention 复杂度从平方级别下降到了线性级别。关于 DETR 和 Deformable DETR 大家可以阅读我之前的两篇文章。
Vision Transformer 在目标检测上的探索,DETR 系列文章解读(一)
Vision Transformer 在目标检测上的探索,DETR 系列文章解读(二)Deformable DETR
今天分享的这些 DETR variants 主要思想就是压缩 DETR 模型的计算量,同时提升模型的检测精度。Effient DETR 通过给 object query 和 reference point 更好的初始化从而减少 decoder 的层数;PnP DETR 和 Sparse DETR 通过从 CNN 出来的 feature map 中选择 salient feature, 仅计算被选择的 feature 之间的 self-attention, 从而减少计算量,差别主要在于选择的方式不一样;
Effient DETR [1]
这篇工作主要探寻一个问题,就是为什么 DETR 需要 6 层 decoder 去更新 object query? 能不能仅用 1 层 decoder 也能达到 6 层的效果?针对这个问题,文章中做了一系列的观察实验。
作者首先分析了 encoder 的层数, decoder 的层数,以及 decoder 的 auxiliary loss 的重要性,如下表所示:
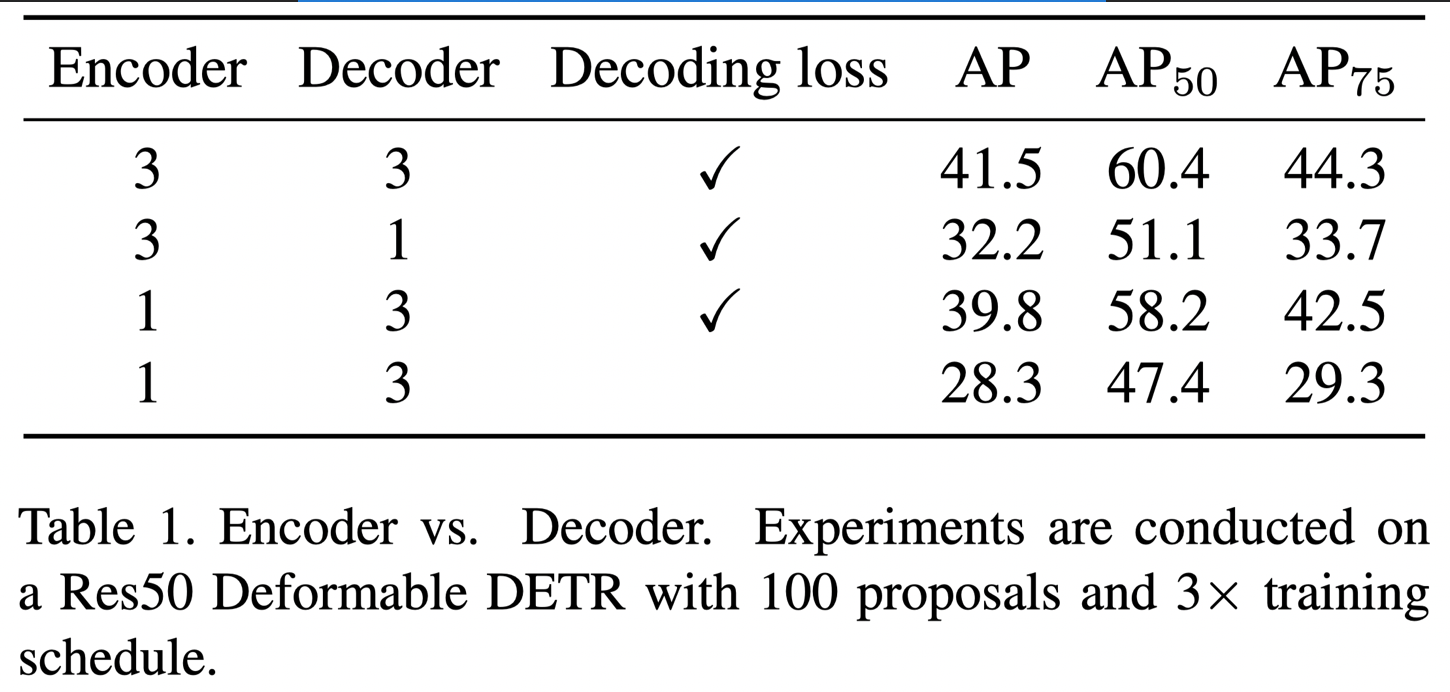
发现 encoder 层数其实没那么重要, 3 层的 encoder 和 1 层的 encoder 相比,掉的点还是比较少的 (41.5 v.s. 39.8),但是 decoder 的层数和 auxiliary loss 对模型的影响就比较大了。作者指出造成这样的结果主要原因是因为,decoder 的 auxiliary loss 给 decoder 提供了很强的监督用于更新 object query. 在我看来 encoder 就是一个特征提取的作用,前面其实有一个 ResNet 网络,特征提取能力也不错了,而 object query 直接与预测结果相关联,但是只有 decoder 能更新它,主要的监督就是来自 auxiliary loss.
文章进一步探讨了如何初始化 object query. 由于 object query 是一堆抽象的 feature, 虽然学习到了一些固定的 pattern, 但是不好直接探索它的初始化和最终学习到的 object query 是什么。作者首先感谢了一波 deformable detr 提出了 reference point 的概念, reference point 是由 object query 通过 linear 层直接预测得到的。通过观察 reference point 在图像中的分布,进一步分析 object query.

上图是 deformable detr 中初始阶段和训练了几个阶段的 reference point 分布图,可以看到,初始的时候基本均匀的分布在整个图像中,但在最后会聚焦于一些 object 上。
所以作者就想到了去探索 reference point 的初始化对结果的影响,如下表:
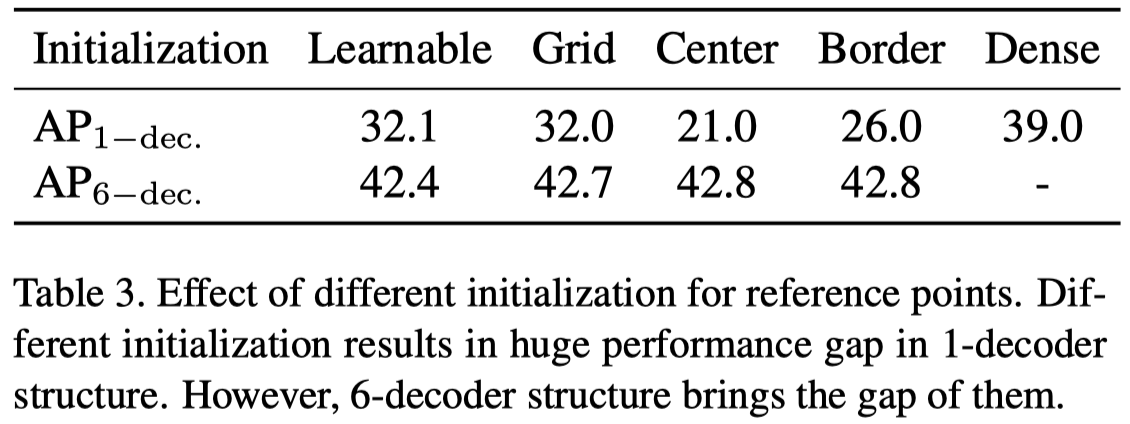
主要的观察就是 6 层的 decoder 无论如何初始化,最终都能学得不错。但是 1 层的 decoder 被初始化影响较大,表中的 dense 就是后面作者提出的方法,后面会详细展开说。
基于以上的观察,作者提出了一个新的方法 Efficient DETR, 只有三层的 encoder 和 1 层的 decoder 在 COCO 上达到 44.2 的 mAP, 并且训练时间更快 (36 epochs).
Efficient DETR 主要包含两个部分: dense 和 sparse, 如下图所示:
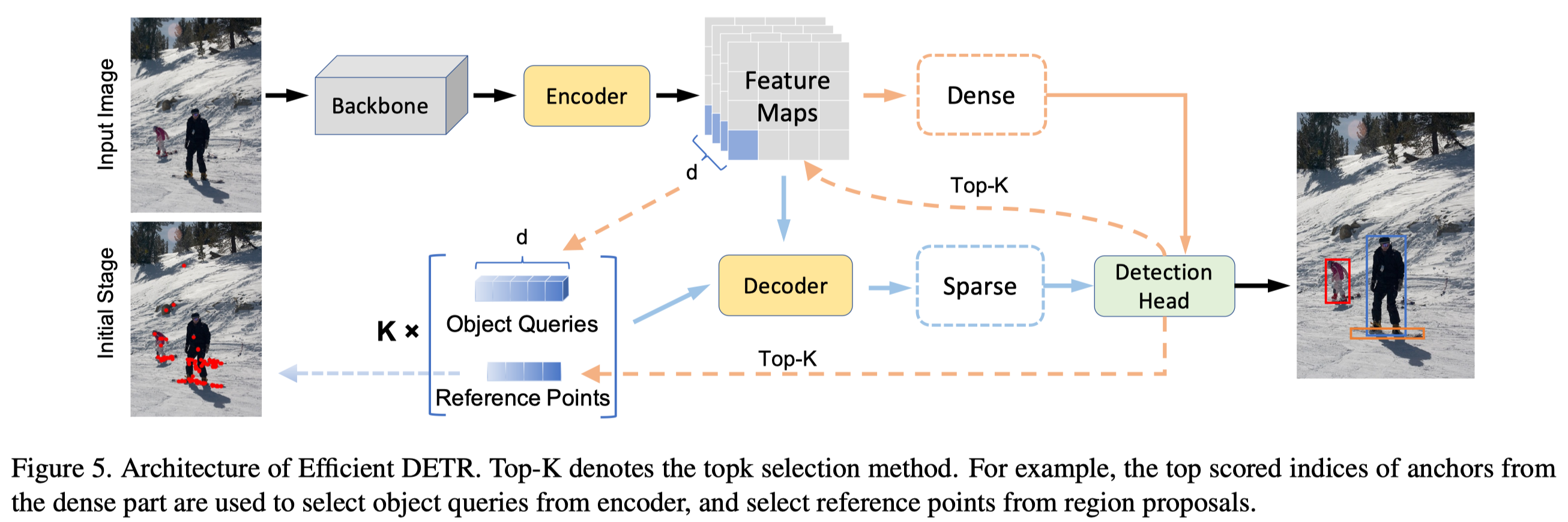
在 CNN 出来的 dense feature map 上预测 top score 的 proposals, 这些 proposal 的 2-d 或者 4-d 坐标用于初始化 reference point. 除此之外,再选择 top-k 的 feature 来初始化 object query.
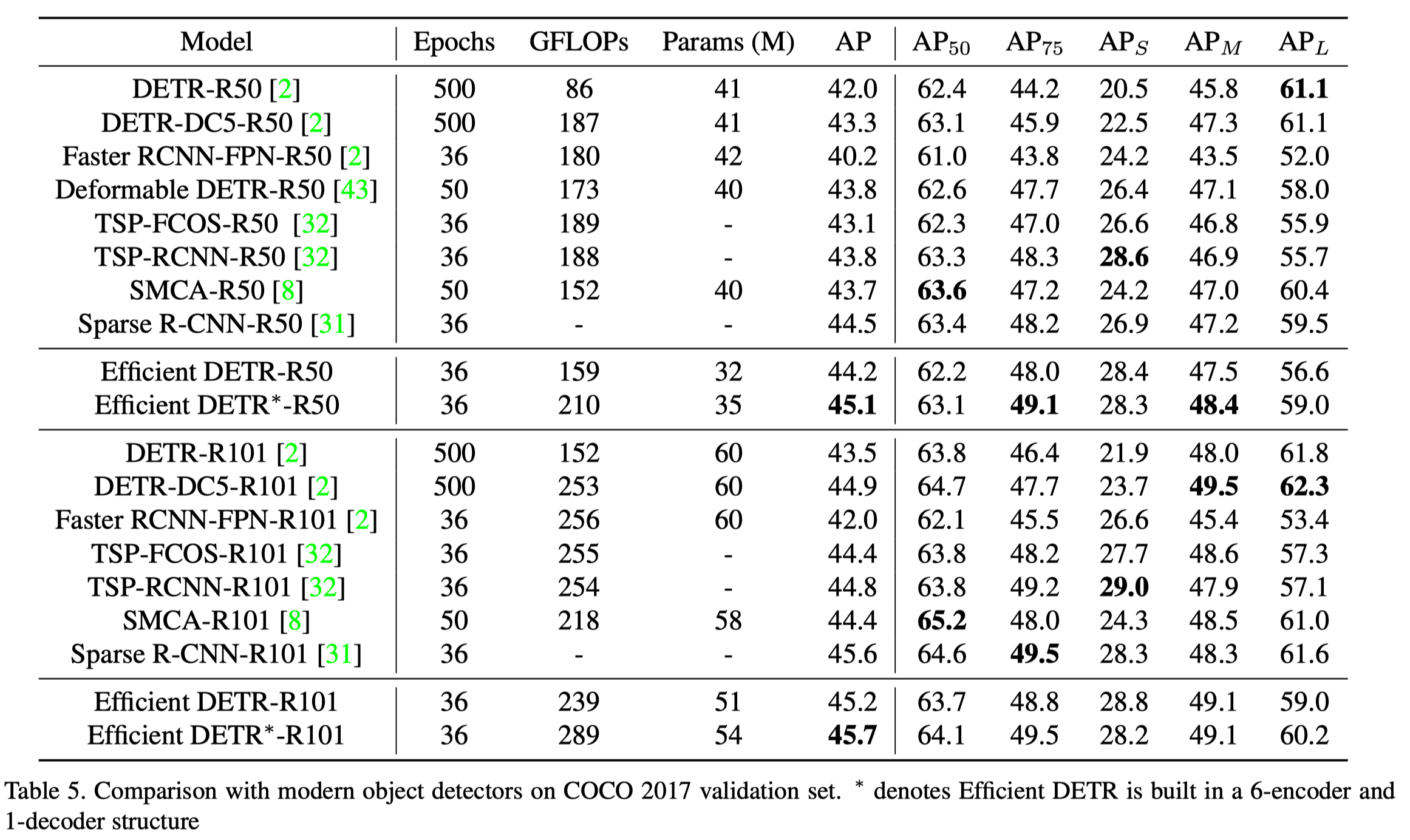
实验效果如上表所示,仅用 3 个 encoder 和 1 个 decoder, 训练 36 个 epochs 便能在 COCO 上达到 \(44.2\) 的 mAP.
PnP DETR [2]
这篇工作的作者认为 DETR 的 Transformer 网络在计算注意力时计算量过高的主要原因在于图像 feature map 的空间特征具有冗余性,即使用 feature map 中所有空间位置的特征来计算 self-attention 是不必要的,可以挑选一些 salient feature 用于计算。因此作者提出了一个两步的 poll-and-pool 采样模块,poll 模块用于在 feature map 中细粒度地采样前景 feature,然后对未采样的 feature 使用 pool 的机制将它们聚合在几个具有 contextual 信息的粗粒度 feature vector 上。经过这两个操作后得到新的 feature set, 基于这个新的 feature set 计算 self-attention.
作者构建了一个 PnP-DETR,PnP-DETR 仅在细粒度的前景 feature 和 粗粒度的背景 feature 之间计算注意力,大大的减少计算量。作者使用一个比例 \(\alpha\) 来确认前景 feature 的个数,固定的 M 值确定背景环境粗粒度 feature 的个数。PnP-DETR 可以实现训练一个模型后调整 \(\alpha\) 达到不同的推理速度。同时,PnP 采样模块比较通用,是一个端到端可学习不需要向 RPN 一样额外监督的模块,可以应用到别的 transformer 框架中,如 ViT。
为了得到这两个集合,作者提出 Poll and Pool (PnP) Sampling 策略,poll sampler 从 CNN 得到的 feature map 中找到前景 feature, 具体来说, pool sampler 使用一个 meta-scoring 网络预测 fature map 所有位置中哪些 feature 是最 informative 的,最终取 \(N=\alpha L\) 个 vector 作为细粒度的前景 feature set。这样就产生一个问题,这个 meta-scoring 网络要怎么学习呢?作者采用的方式是把预测的 score 作为 feature 的一个 modulating factor, 即:
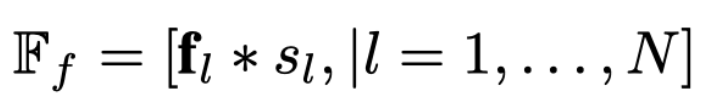
通过这样的方式,作者让 meat-scoring 网络的学习做到了端到端,不需要向 RPN 那样用一个额外的显式地监督来学习,都隐含在最终的任务中了。
对于没有被采样的 feature, 作者认为这一部分包含了很多物体周围的环境信息,但由于计算量的考虑,不应该都用来计算注意力机制。所以作者提出了一个 pool sampler 采样,即用一个可学习的权重来聚合这些背景 feature, 最终得到 M 个 feature. 作者将 poll 和 pool 得到的 feature 作为一个集合,用于后续的注意力计算,通过采样将原本 \(L=H*W\) 个 feature 转化到了 \(N + M\) 个,减少了很多计算量。
除了检测任务,作者还希望让模型能够做 Dense Prediction 任务,比如 segmentation, 但是由于 feature 经过了采样,不太适合这类任务。针对这个问题,作者提出 Reverse Projection 的操作,将采样得到的 feature 扩散回原来的 feature map. 对于 poll 的 feature, 直接安排到原来的采样位置就好。那对于经过权重矩阵聚合的 pool feature 怎么办呢?作者的方法也很简单粗暴,再用一个权重矩阵映射回去就行了。
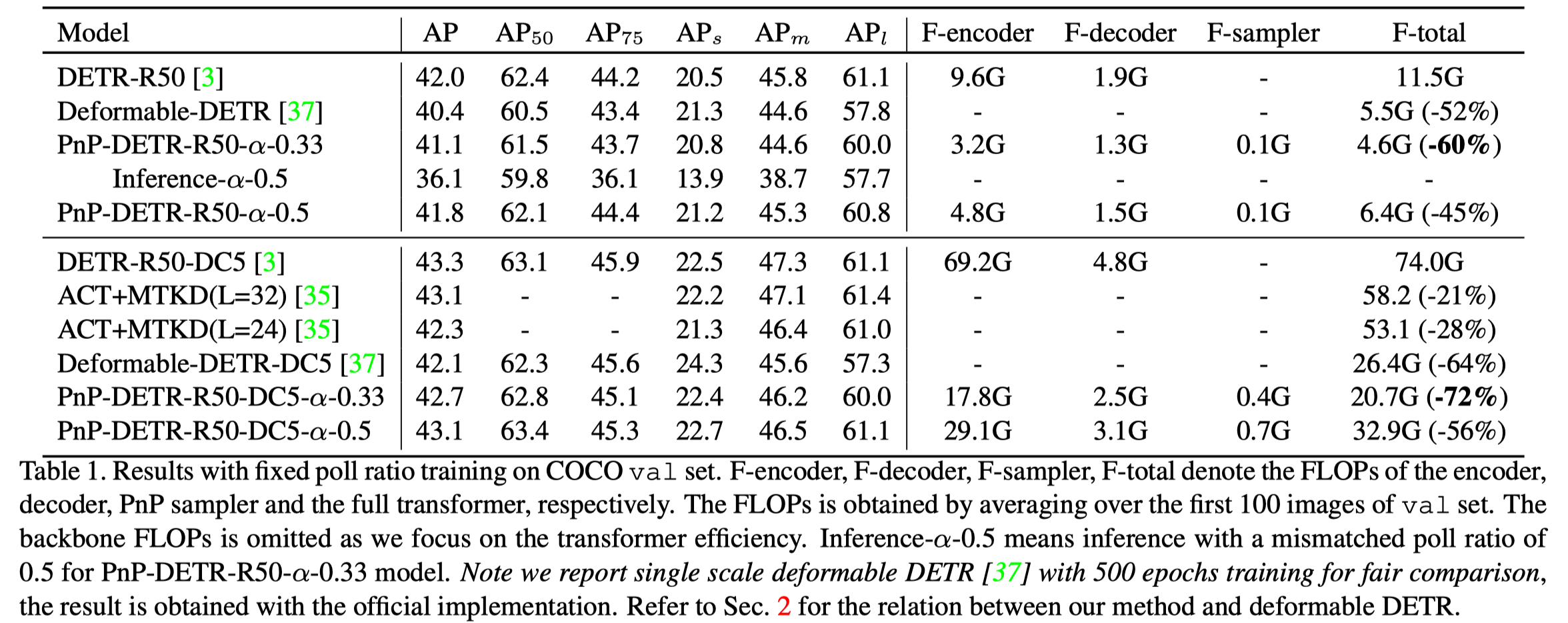
实验结果在 DETR 中不算很高,在 res50 上能达到 43.1 的 mAP, 同时减少了 50% 的计算量。当减少 66% 时,能达到 42.7 的效果,值得注意的是单尺度的 deformable DETR 也能达到 42.1 的结果,但 Pnp DETR 计算量更少。除此之外,这个方法还有一个优点,作者提出的这个策略通过调整采样率能够在推理的时候动态地调整,从而改变推理速度并使得精度波动不大。
Sparse DETR [3]
这篇工作提出 Sparse DETR, 主要的 motivation 是解决 DETR 方法中 encoder 计算量过大的问题。假设 feature map 大小为 H*W, 那么转化为序列长度为 L=H*W, DETR 计算两两之间的 attention, 复杂度是 N 的平方。Deformable DETR 使用 deformable attention 代替 DETR 中的全局 attention, 稀疏化 key 从而减少计算量,从平方复杂度降低到了线性复杂度,N*k (k«N, k=4, in deformable DETR),才使得模型可以使用多尺度的 feature, 进一步来提升模型的性能。但是由于多尺度的引入,encoder 的 tokens(query) 增加了很多,因此计算消耗仍然是 encoder attention 的瓶颈。
同时,作者观察到其实仅仅更新 encoder 中的一部分 tocken 并不会造成太大的性能下降,因此作者提出稀疏化 encoder tokens(query), 具体的 attention 复杂度比较如下图所示:
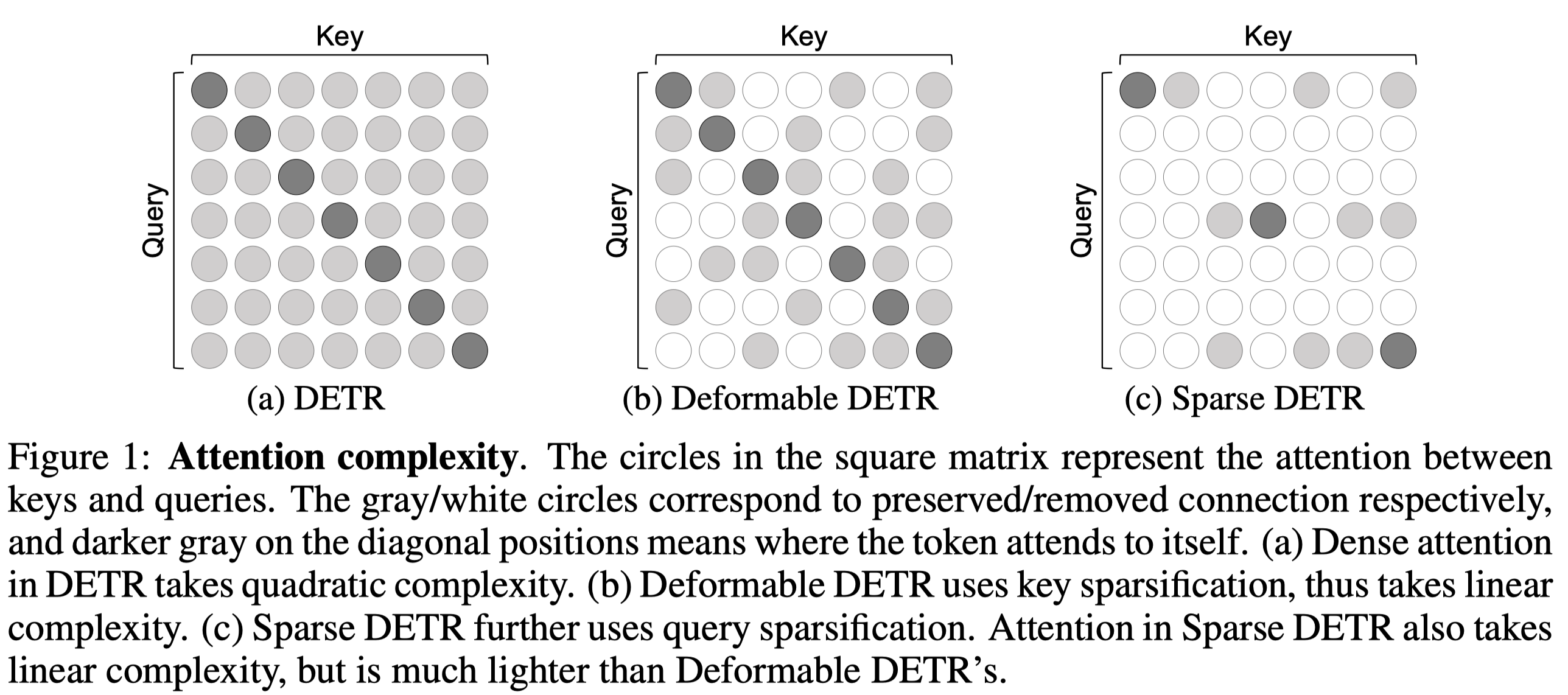
其中黑点是自己和自己的 attention, 灰色的圈是保存下来的 attention 连接,白色的圈是去掉的 attention 连接,可以看出 Sparse DETR 相比 DETR 和 Deformable DETR 降低了很多的计算量。
为了实现 token 的稀疏化,作者提出两个方法来挑选 saliency 区域,分别是 Objectness Score 和 Decoder Cross-Attention Map. 除此之外,作者基于稀疏后的 token 提出两个额外的组件: Encoder Auxiliary Loss 和 Top-k Decoder Queries. 前者对 encoder 也使用辅助的 detection 监督损失,和 decoder 的 Auxiliary Loss 是一样的,可以这样的主要原因还是因为 encoder 的 token 被压缩了,不然对每个 token 都计算 auxiliary loss 的计算量太大了。后者就是把可学习的 decoder query 替换为从 encoder 中选择的 top-k token,和 PnP DETR 的方法差不多.
前面提到作者提出了两种方法来找到最 salient 的 encoder tokens: 分别是 Objectness Score 和 Decoder Cross-Attention Map.
Objectness Score 方法比较简单,就是在 feature map 后面添加一个检测头然后用 Hungarian loss 监督,这样选择分数比较高的用于后续 attention 计算,论文里面选择 \(top-\rho %\) 个 tokens. 这样的方法其实在很多检测方法中有使用,比如 RPN 就是在 feature map 上直接计算 objectness score. 尽管这样的方法能够找到一些 salient 的 encoder tokens, 但是这样的操作和 decoder 是独立的,没有充分考虑 decoder.
所以作者提出了 Decoder cross-Attention Map(DAM), 用 decoder 的 cross attention 来做为评价指标。直观上理解就是,对 object query 响应值高的 token, 天然地对最终的检测结果更为重要,所以应该保留用于计算得到最终的检测结果。如何得到这个 DAM 呢? 对于 dense attention, 直接把 decoder 的每一层 cross attention 加在一起就可以;对于 deformable attention, 计算每个 object 的对应偏移后的 attention 就可以了。作者把这个 DAM 二值化,使用一个 scoring network 来预测这个 DAM, 用 BCE loss 来监督,如下:
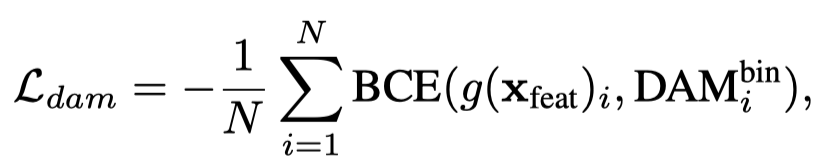
其中 \({DAM}_i\) 是指第 \(i\) 个 encoder token 对应的 DAM.
这里有一个问题是在 feature map 后选择的 token 就确定了,未被选择的 token 就固定下来了,虽然 deformable attention 和它们会有交互,但是它们的值永远不会变,感觉可以考虑把这个选择的过程嵌入到每一个 encoder layer 后,感觉性能会有进一步的提升?
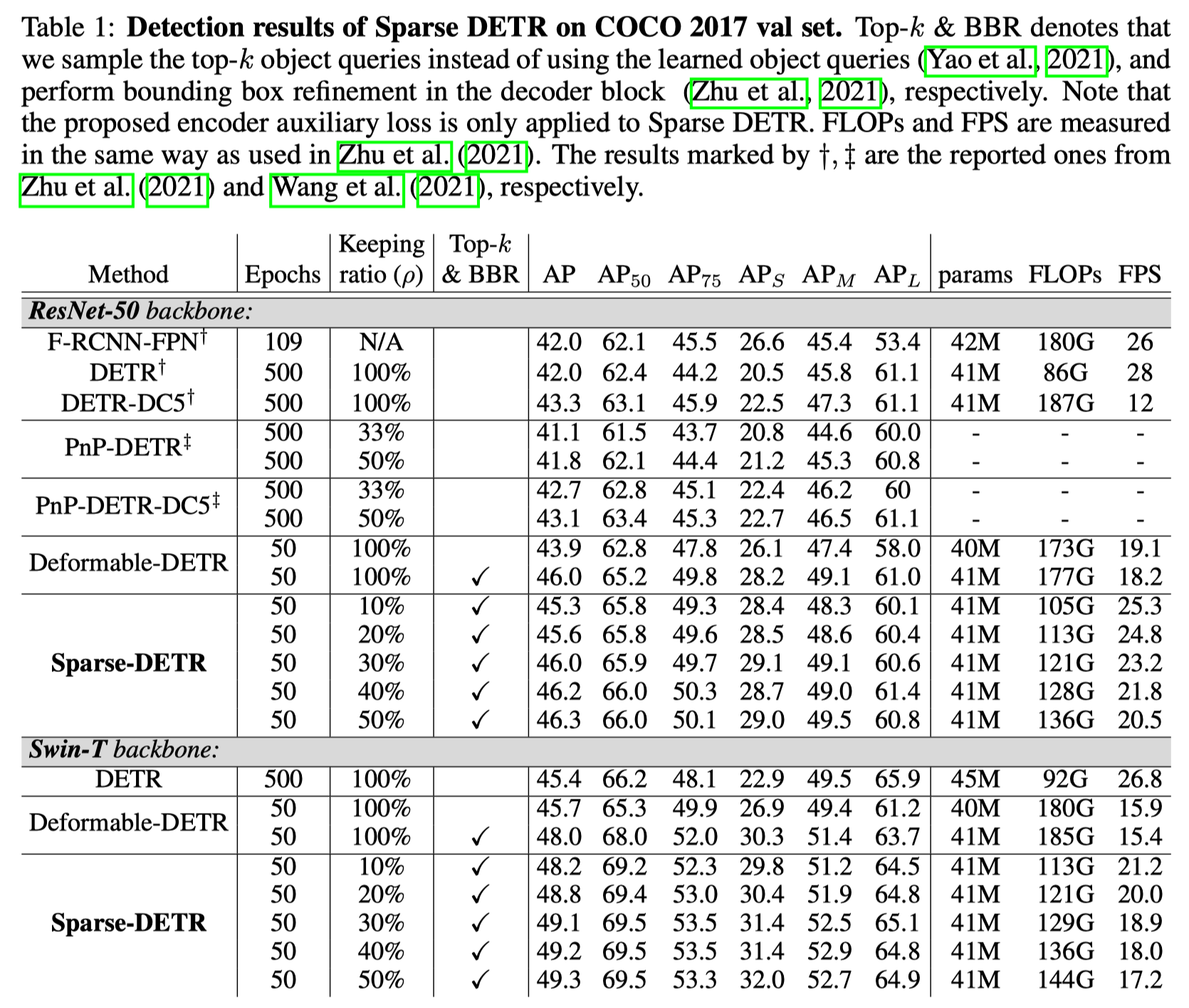
实验结果如下图,在更小计算量的同时性能超越 Deformable DETR. 作者将 ResNet 换成 Swin-T 时,效果更佳,达到了 \(49.3\) mAP.
总结
这篇文章主要介绍了 Effient DETR, PnP DETR, Sparse DETR, 这几篇工作都在为减少 DETR 中计算 self-attention 的计算量努力,都取得了不错的效果。本文只能算抛砖引玉,对于想要深入研究的同学,还是需要仔细阅读原论文才行。除了本文介绍的工作,一篇工作提出 Adaptive Cluster Transformer (ACT) [4] 压缩 DETR 模型大小, 使得推理时计算量大大减少,ACT 主要通过计算 encoder 的 token 之间的相似性得到 prototype 从而压缩 token 数量,同时提出 DETR 模型的蒸馏方法提升压缩模型的性能,感兴趣的朋友也可以去看看原论文。
本篇文章这是 DETR 系列的第三篇文章,接下来将整理 DETR 的另一个优化方向的论文,通过加入更多的先验知识从而提升模型的收敛速度和精度,包括但不限于:
- Fast Convergence of DETR with Spatially Modulated Co-Attention(SMCA)
- Anchor DETR: Query Design for Transformer-Based Detector
- Conditional DETR for Fast Training Convergence
写文不易,希望各位看官点个赞再走 vov
Bibliography
[1] Z. Yao, J. Ai, B. Li, and C. Zhang, “Efficient DETR: Improving End-to-End Object Detector with Dense Prior,” arXiv preprint arXiv:2104.01318, 2021.
[2] T. Wang, L. Yuan, Y. Chen, J. Feng, and S. Yan, “PnP-DETR: towards efficient visual analysis with transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 4661–4670.
[3] B. Roh, J. Shin, W. Shin, and S. Kim, “Sparse DETR: Efficient End-to-End Object Detection with Learnable Sparsity,” arXiv preprint arXiv:2111.14330, 2021.
[4] M. Zheng et al., “End-to-end object detection with adaptive clustering transformer,” BMVC, 2021.