前言
针对 DETR 收敛慢资源消耗多,小目标检测难的问题,Jifeng Dai 团队做出了 Deformable DETR,根据 Deformable convolution 的思想对 DETR 进行改进,即让注意力模块只注意到参考点周围的少量样本点。如下图所示,作者提出的 Deformable DETR 把多尺度的 feature map 送入 encoder 中,在 encoder 中,下一层的 feature 由上一层的参考点周围的少量点决定,最终将 encoder 的多次度特征再送到 decoder 中,最终输出预测的结果。
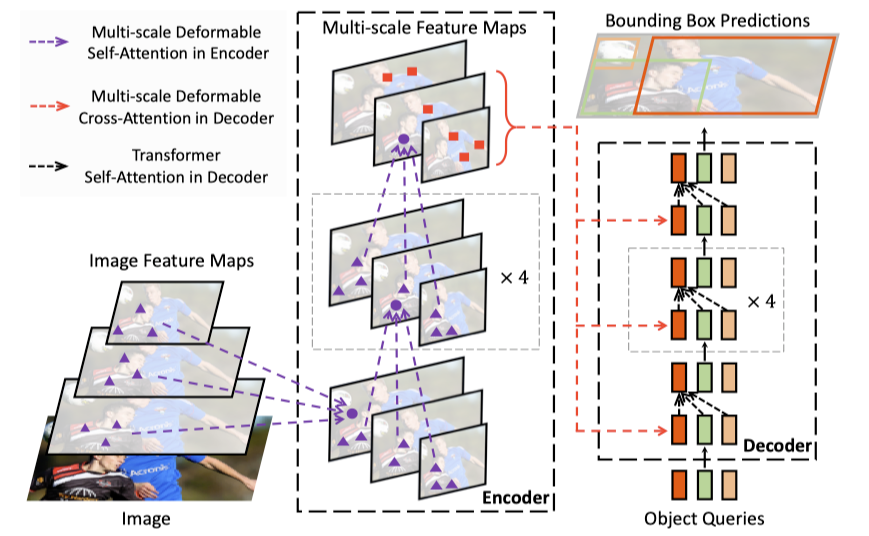
正文
Deformable DETR 的核心在于 Deformable Attention Module,该模块用于直接替换 DETR 中的 multi-head self-attention 模块,由于 Deformable DETR 在计算 attention 的时候只考虑参考点周围的几个偏移点,大大的减少了计算量,因此也可以使得模型能够扩展到 multi-scale,进一步提升模型在不同尺度目标上的检测性能。
Deformable Attention Module
Deformable DETR 的主要贡献便是提出了一个 Deformable Attention Module 的模块,该模块可以用于替换 encoder 中的 self-attention 模块,能极大地减少计算量。由于 query feature 仅与参考点周围的 K 个样本做交互,实现中 K=4,因此计算量大大减少。减少计算量的同时,由于限制了 attention 的范围,相当于加入了一些先验知识,使得模型收敛更快。
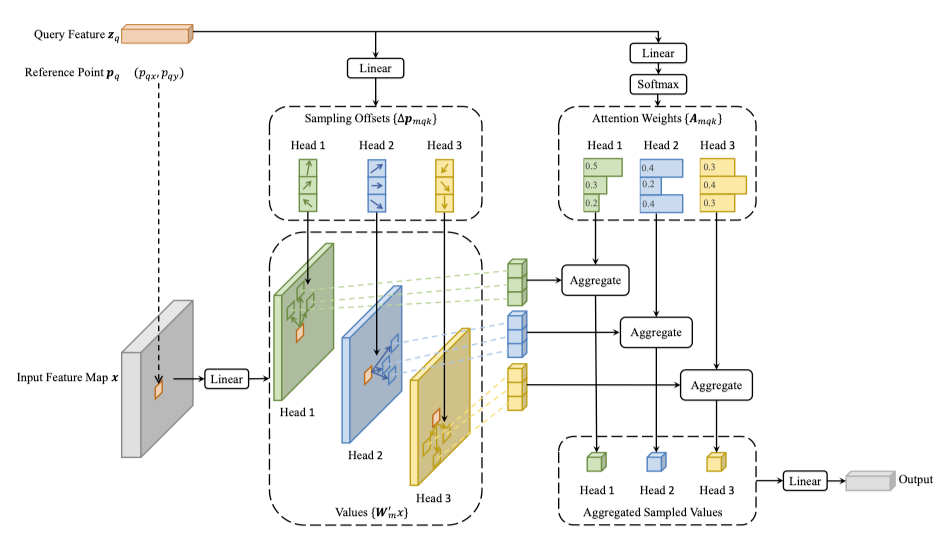
Deformable Attention Module 的具体设计入上图所示,首先一个 Query Feature \(z_q\) 经过两个 linear 层,分别生成 \(2*MK\) 和 \(MK\) 的 offset 和 attention weight。根据对应的参考点(其实就是 query 在 feature map 中的位置)预测 offset,计算新的坐标点,采集这些新坐标点特征并用 attention weight 进行加权融合信息,最终将多个 head 的信息 concat 到一起。形式化的定义如下:
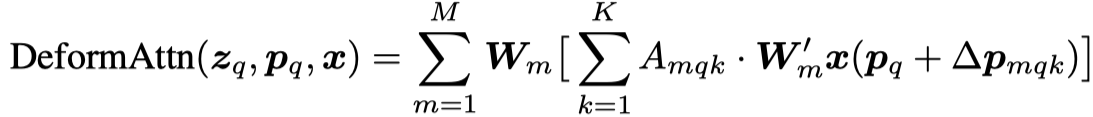
其中 x 是一个 \(C*H*W\) 的 feature map, \(\boldsymbol{W}_{m}^{\prime}\) 是一个 1*1 的卷积层,用于降低 channel 的维度, \(\boldsymbol{p}_{q}\) 是参考点, \(\Delta \boldsymbol{p}_{m q k}\) 是用 query feature 预测得到的 offset,从feature map 中得到参考点 \(\boldsymbol{p}_{q}\) 周围的特征,通过 attention weight 加权求和得到新的 feature。
Multi-scale Deformable Attention Module
为了解决多尺度目标检测的问题,作者提出了 Multi-scale Deformable Attention Module,主要的差别是将不同层的 feature 融合在一起,多了一个 scale 的维度,如下:
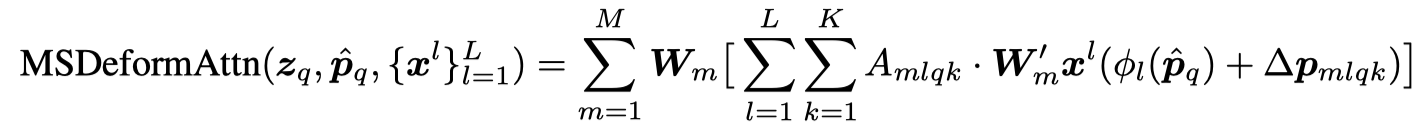
其中 \(\phi_{l}\) 是一个映射函数,将参考点的位置映射回对应的 feature map 层级。
Deformable transformer encoder
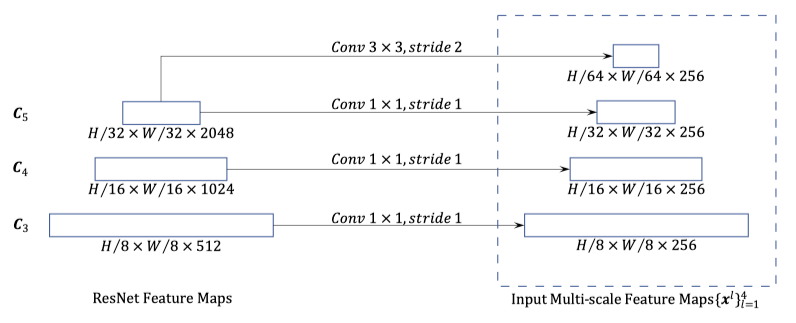
在实现上,作者使用了四层的 feature map 作为多尺度特征,前三层是 ResNet 的 \(C_3\) 和 $C_5$,最后一层通过在最后的 \(C_5\) 层后加一个 \(3*3,stride=2\) 的卷积层得到,记为 \(C_6\) 。所有的多尺度 feature maps 都转化为同一个 channel 大小 \(C=256\) ,入下图所示:
为了在学习过程中,模型能够知道对应的特征来着哪一个层级,作者在 positional encoding 里面还加入了随机初始化科学系的 scale-level 的 positional encoding。
Deformable transformer decoder
在 decoder 中,每一个 decoder layer 有 self-attention 和 cross-attention 两个部分,self-attention可以直接从计算 object query。而 object query 在 cross-attention 对应的参考点则使用一个可学习的 linear layer 来学习。由于最终抽取的特征是在一个参考点周围的图像特征,所以作者将检测头也设计为预测针对参考点的 offset 而不是绝对坐标。
Deformable DETR 的两个变体
作者还设计了两个 Deformable DETR 的变体,分别是进行迭代式的 bounding boxes 修正,以及 two-stage Deformable DETR。
- 迭代式的 bounding boxes 修正
decoder 的每一层修正上一层的预测,即上一层的预测的结果输入到下一层。
- Two-Stage Deformable DETR
从 two-stage 目标检测器得到启发,作者首先利用一个 FFN 在 encoder 的 feature 上得到初始的 region proposal,挑选其中分数较高的 proposal 用于后续的优化。具体来说,作者将分数较高的 proposal 当做迭代式的 bounding boxes 修正的初始点。
总结
Deformable DETR 通过将 Deformable Conv 的思想引入 DETR,不仅减少了计算量,而且提高了模型的收敛速度。在实验部分,Deformable DETR 仅需要 50 epochs 便能达到 DETR 需要 500 epochs 达到的效果,相当于 10x 的收敛速度,而且精度更高。