前言
DETR(Detection Transformer) 将 CNN 与 Transformer 相结合,把检测任务当做集合预测 (set prediction) 任务,实现真正的 end-to-end 目标检测模型,即不需要任何的后处理阶段,比如 NMS 去除冗余框,直接从图片的原始像素得到最终的目标框和坐标预测。DETR 是 2020 年 5 月的文章,是早于 ViT (2020年10月),可以说 DETR 是 Vision Transformer 的奠基作品之一,不仅改变了大家对目标检测的一些固有看法,而且给后续 Vision Transformer 的发展具有重要意义,目前的引用量也有 1200+ (21 年 12 月)。
正文
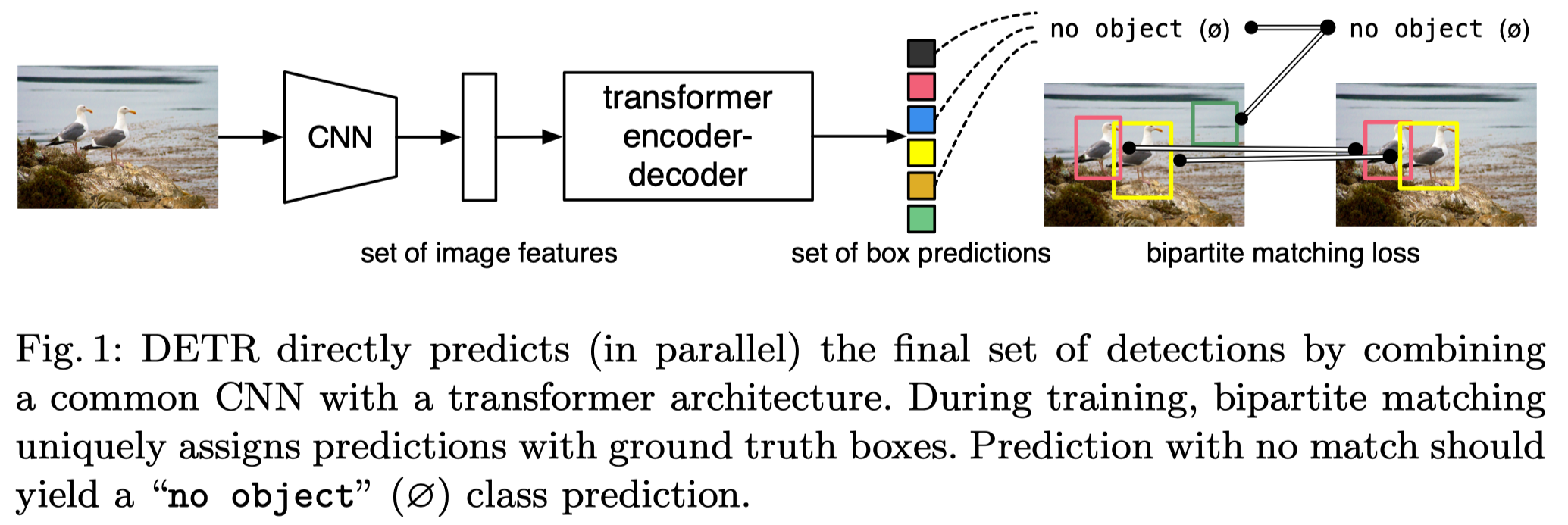
如上图所示,DETR 整个结构非常简单,主要包括一个 CNN 模块用于从图像中提取特征和一个 Transformer encoder-decoder 模块直接产生一系列的目标框预测,图中的二分图匹配(bipartite matching)loss便是不会产生冗余框预测从而去除 NMS 的关键。具体来说,给定一张图片,通过 CNN 提取特征,将特征拉平作为序列输入到 transformer 中,然后直接预测 N 个目标框,每一个预测的目标框将与 ground truth 进行一对一的最优匹配,没有匹配上的预测框将被赋为空,即为图中的 no object,其实就是背景类。
通过前面对整个架构的了解,可以看出 DETR 主要有两个关键的部分:
- 二分图匹配 bipartite matching loss 的设计
- DETR 模型结构
接下来对这两部分进行详细的介绍。
二分图匹配 bipartite matching loss 的设计
bipartite matching loss 的核心就是做匹配,把预测的结果和 ground truth 做一一匹配。假设有 N 个预测,每个预测包含坐标框和类别概率,ground truth 也是有 N 个元素的集合(通常 ground truth 目标框的个数少于预测的目标框,剩余的部分用 no object 填充)。为了找到最优匹配,通过搜索预测结果中 N 元素的最优排列,使得两个集合对应元素有最小的 cost:
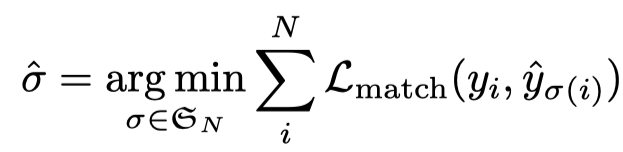
即找到 N 个预测结果与 ground truth 一一对应的匹配损失,得到 ground truth 每一个元素对应预测结果最小代价的 index。这样的匹配算法其实就是匈牙利匹配,Hungarian algorithm, 很多代码库都有相应的实现,直接可以利用。这里的 \(\mathcal{L}_{match}\) 包含了预测分类分数和定位两个指标,如下:
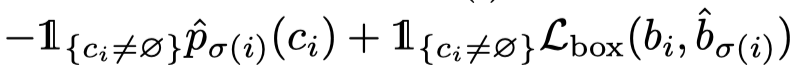
有了最优的匹配之后,便可以计算损失函数,主要包括两个部分,一个是类别预测的 negative log-likehood,另一个是 bounding box 的回归损失:
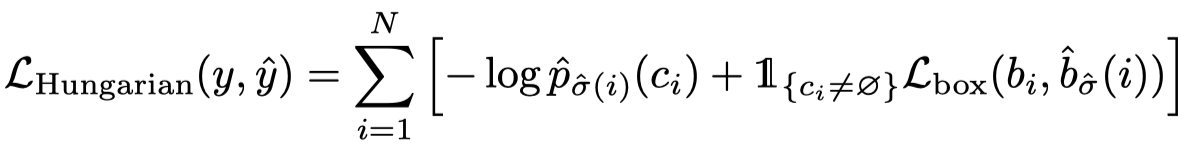
这里的回归损失函数包含两个损失,即 GIoU 损失和 L1 的损失:
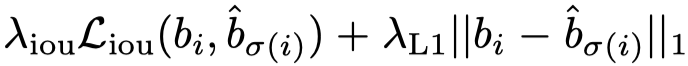
DETR 模型结构
前面已经讲解完训练损失的关键部分:bipartite matching loss,接下来开始更加细致地分析 DETR 的整体结构,看看 transformer 在目标检测中可以怎样设计。模型的详细结构图如下所示:
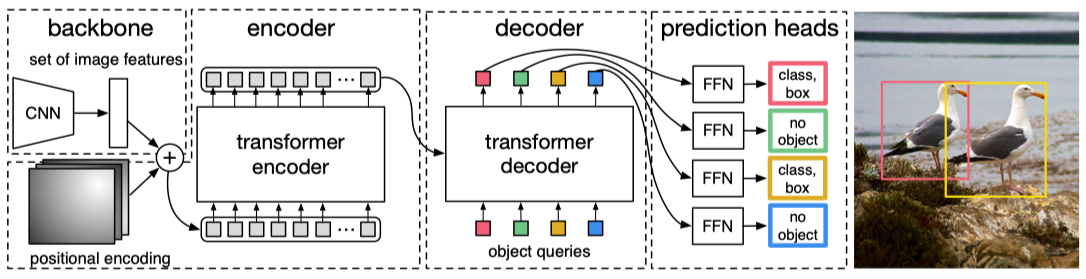
总共包括四个部分:CNN骨干网络 backbone、encoder、decoder,prediction heads,接下来分别介绍这四个部分。
1) CNN 骨干网络 backbone DETR 利用 CNN 骨干网络从原始像素值中提取特征,假设一张图的大小为 \(3*H_0*W_0\) , 通过 backbone 之后,以 resnet50 为例,将会得到一个 feature map,大小为 \(C*H*W\) ( \(H=H_0/32\) , \(W=w_0/32\) , \(C=2048\))。
2) encoder encoder 首先使用一个 \(1*1\) 的卷积来减少 feature map 的维度,把 C 变成一个更小的维度 d, 得到一个新的 feature map \(d*H*W\) 。由于 encoder 希望得到的输入是一个序列,所以 DETR 把空间维度拉直变成了一维,得到一个 \(d*HW\) 的feature map,其实就是原始 feature map 中的一个点代表 nlp 里面的一个词。
DETR transformer 的 encoder 与标准的 transformer 基本一致,如下图所示:
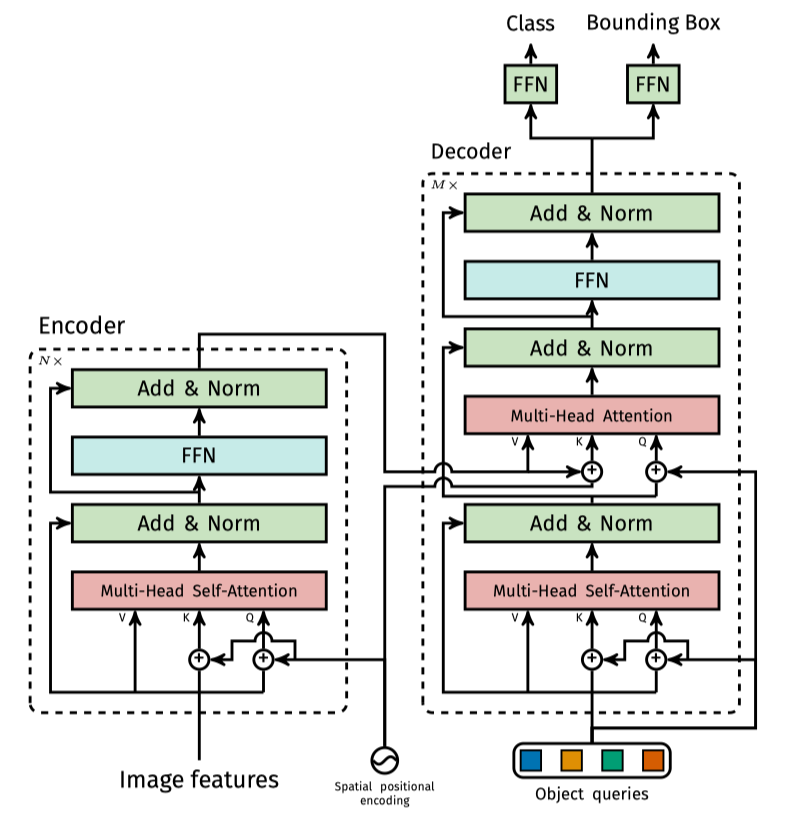
encoder 部分主要包含一个 multi-head self-attention 模块以及一个 FFN 网络。虽然整体结构和标准的 transformer 基本一样,但是还是有一些不同的地方。
a) 考虑 2d 空间的 Spatial positional encoding
传统的 transformer 的 position encoding 都是 1D 的,但是对于视觉任务,很明显具有 2D 的关系,因此作者设计 Spatial positional encoding 考虑了两个 xy 两个方向,具体的编码方式采用的是 sincos 的形式。因为 position encoding 最后是要和feature相加的,所以它的维度也是 d 维,在实现上就是先对 x 方向进行编码得到维度维 d/2 的向量,再对 y 方向进行编码同样得到维度为 d/2 的向量,最终将二者 concat 到一起。
b) 仅 K 和 Q 上添加了 Spatial positional encoding
这里给出标准 transformer 的结构图示意图:
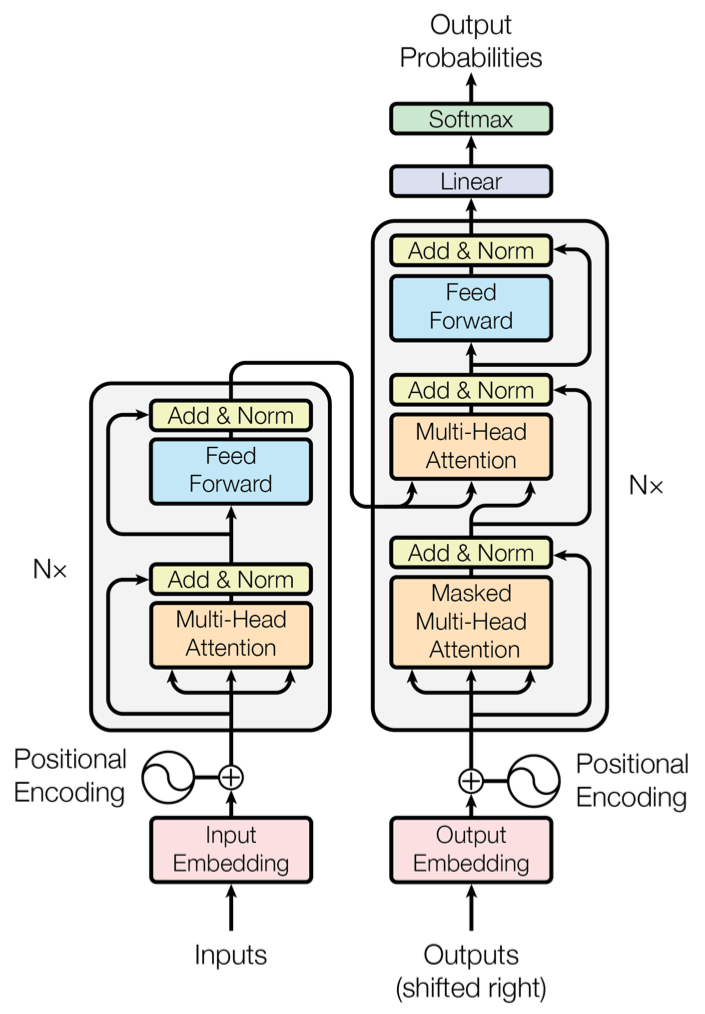
可以看到 positional encoding 是加在 Q,K V 上的,而 DETR 这里仅加在了 Q 和 K 上,作者也没解释为什么这样加,大概因为目标检测任务对位置更加敏感,所以在整个过程中都加入位置信息。
3)decoder
DETR transformer 的 decoder 和标准的 transformer 的 decoder 有很多的不同之处。
a) 并行解码所有元素
由于预测的目标之间是无序的,DETR可以一次性将 N 个目标框预测出来,因此在解码时不需要向标准的 transformer 一样进行顺序解码。回想一下标准 transformer 解码器的工作流程,首先输入一个起始的 token BOS_WORD, 然后解码器预测第一个元素,将开始 BOS_WORD 和第一个元素送入 decoder,然后得到第二个元素,依次进行下去知道得到结束的 token 才终止。然而在 DETR 中,只需要初始化一个全 0 的token,然后加上对应的 position encoding(文章叫做 object query,后面将详细阐述)一起送入到 decoder 中,直接得到 N 个目标框的预测结果。
b) Object Query
DETR 中在 decoder 部分提出了一个 Object Query 的概念,可以简单理解为标准的 transformer 中的 position encoding,形式上差不多。但是在 DETR 中主要是为了得到目标物体与全局图像之间的关系,简单来说就是一些关于目标在图像中的一些关系,比如大小、位置、类别等信息,每一个 query 相当于融合和了整个数据集中所有类别在某个位置具有多大的目标。Object query 首先计算一个 self-attention,然后和 encoder 得到的 k,v 计算新的 feature。值得注意的是,这里计算 self-attention 的时候,object query 和 encoder 的 positional encoding 一样,也只加在了 k,q 中,没有加到 v 上。
c) decoder 中计算 cross-attention 时都加上了 positional encoding
仔细对比标准的 transformer 的 encoder 和 DETR 的 encoder 可以发现,标准的 transformer 在 decoder 中,接收的 encoder 输出没有添加 positional encoding,而在 DETR 中,作者认为 positional encoding 在 decoder 中也非常重要,主要还是因为目标检测是一个和位置强相关的任务。
4)Prediction Heads
Prediction Heads 主要是得到分类结果和目标框的坐标,就是一些全连接层,比较简单。除了最后一个 decoder 计算损失函数外,作者添加了一些辅助的损失函数,就是将每一个 decoder 的输出都用同样的 prediction Heads 来计算损失,这样可以进一步提升模型的性能。
实验结果
在实验部分,backbone 主要是 resnet50/101,以及为了提升特征的分辨率,使用了空洞卷积,最后得到的 feature 少降低一倍分辨率,当然分辨率的提高也引来了更大的计算消耗。
主要的实验结果如下表所示:
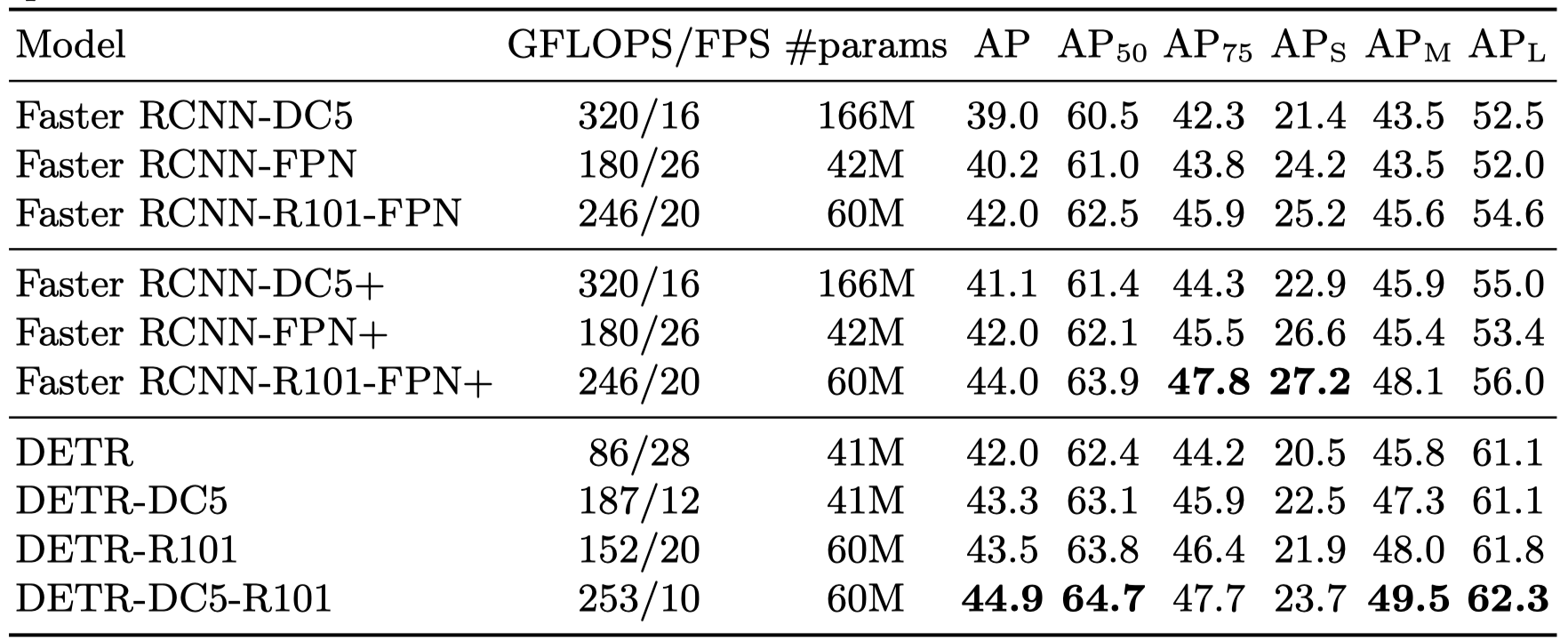
图中的模型都是通过 Detectron2 来实现的,普通的 Faster RCNN 训练 3x schedule ,然后 “+” 代表 9x schedule (109 epoches),可以看到 DETR 模型的效果基本可以达到甚至超越 Faster RCNN 的结果。但是从表里也可以发现 DETR 的一些劣势,特别是在小目标上的检测精度上。
作者对模型做了很多消融实验并且提供了很多的图示进行解释。
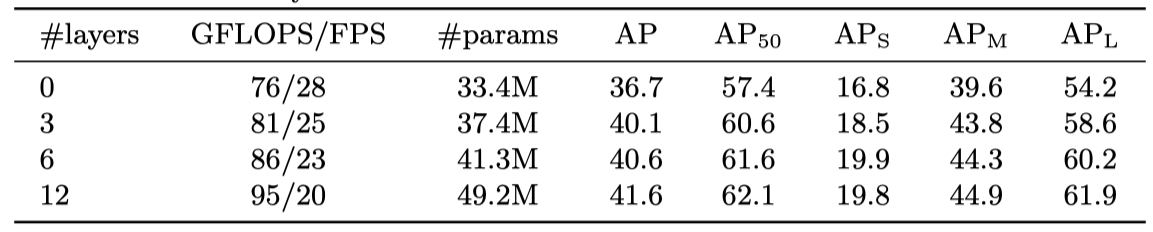
encoder 的层数
结论是基本上 encoder 的层数越多,效果是越好的
encoder self-attention 可视化
作者对最后一层 encoder 出来的 attention maps 进行了可视化,选取了几个目标中的参考点,然后可视化对于参考点的 attention,可以看出这些参考点的 attention 已经能够将目标区分出来,这样可以简化后面 decoder 的精确定位。
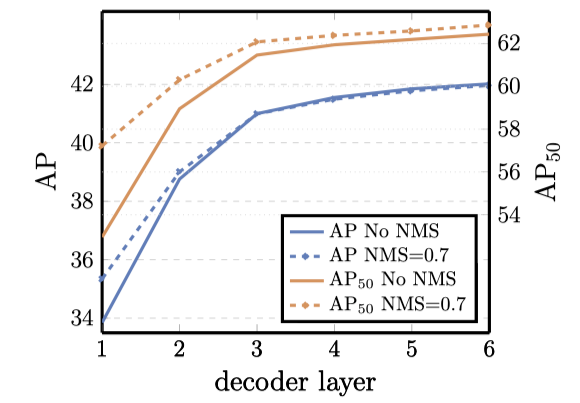
decoder 的层数
DETR 的每一层 decoder layer 都会输出对应的预测结果,作者对每一层输出的预测结果进行评估,可以发现当然层数是越多越好,而且 DETR 不需要进行 NMS,说明 DETR 不会产生冗余的预测。
decoder attention 可视化
同样地,作者对 decoder 的 attention 也进行了可视化,每一个能够检测到目标的 query,对应的 attention 如上图所示,可以看出 decoder 的 attention 激活值比较大的地方确实主要在目标的边界。
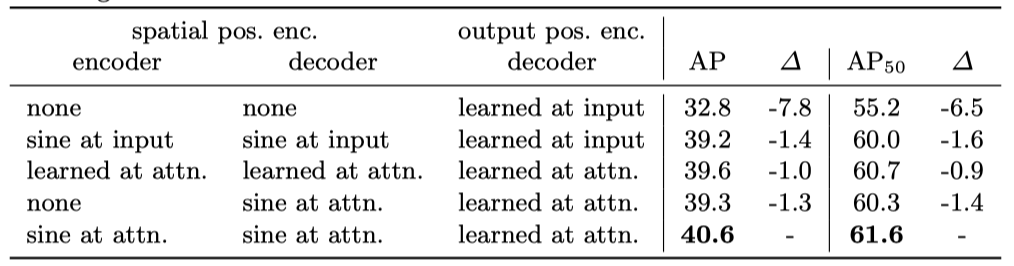
positional encoding 的重要性
DETR 中有三个地方需要 positional encoding,一个是 encoder 的输入,一个是 decoder 的 cross attention 的部分,最后一个是 decoder 的 self-attention 部分。表中 at input 表示只在 encoder 或者 decoder 的输入的地方添加 positional encoding,这是标准的 transformer 中使用的策略。at attn 就是 DETR 的方式,在 encoder 或 decoder 每一层都添加了对应的 position encoding。由于 object query 是必须的,所以作者在这个实验没有去除 decoder 的 object query。从表中可以看到,如果去除 encoder 和 decoder 中的 positional encoding 后,模型的检测精度将会极速下降。
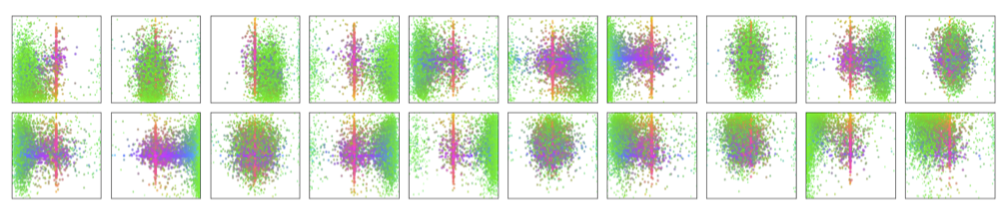
decoder output slot 分析
这里的 decoder output slot 其实就是 object query,作者通过可视化 COCO 2017 val 数据集上所有图片的 box 预测结果,从 100 个预测中选取了 20 个 DETR decoder 的结果。其中不同的颜色代表点代表 box 的不同大小,绿色为小目标,红色为大目标。点的位置代表了目标的中心位置。可以看出,不同的 object query 学习到了在某个位置,特定大小目标的 patten。作者提到 COCO 数据集中就存在很多和图像大小差不多的 box,所以大多数 slots 都会预测中心区域然后很大的目标框。
泛化到没有见过的目标数量
COCO 数据集中很多目标都不会出现太多次,特别是一个类别的目标不会在图像中多次出现,所以一个很自然的疑问就是 DETR 能够泛化到未知目标数量的图像上吗?因此作者做了一个实验,将 24 个长颈鹿拼在一起,然后送入 DETR 模型检测,可以看到模型依然能够检测出来,这说明 每个 object query 不会有很强的关于类别的偏见。



个人评价
毫无疑问 DETR 是一个开创性的工作,直接把 transformer 引入到目标检测中,把目标检测任务当做一个点集预测的任务,实现目标检测真正的 end-to-end。但是也有一些问题:
- 不够纯粹。在刚出来的时候,很多人认为 DETR 是一个残次品,是 CNN 和 transformer 的组合。所以没有引起很多的关注,知道 ViT 的出现,vision transform 才开始急速发展。
- 收敛速度慢,资源消耗多。DETR 训练需要的资源消耗也让很多人望而却步,作者在 COCO 数据集上训练 DETR 需要至少 300 epoch,使用 16 张 V100 需要训练三天才能收敛。
- 在小目标上表现欠佳。
后续基于 DETR 的工作主要集中解决后两个问题,使得模型收敛更快,性能更好。